
Data Model#
oneDNN Graph uses logical tensor to describe data type, shape, and layout. Besides 32-bit IEEE single-precision floating-point data type, oneDNN Graph can also support other data types. The shape contains multiple dimensions, and the total dimension and the size of the dimension could be set as unknown.
oneDNN Graph uses the following enumeration to refer to data types it supports. Different operation may support inputs and outputs with different data types, so it’s suggested to refer to the definition page of each operation.
enum dnnl::graph::logical_tensor::data_type
- undef
Undefined data type (used for empty logical tensor).
- f16
- bf16
- f32
- s32
32-bit signed integer.
- s8
8-bit signed integer.
- u8
8-bit unsigned integer.
oneDNN Graph supports both public layout and opaque layout. When the
layout_type of logical tensor is strided, it means that the tensor
layout is public which the user can identify each tensor element in the physical
memory.
For example, for \(dims[][][] = {x, y, z}\), \(strides[][][] = {s0, s1, s2}\), the physical memory location should be in \(s0*x+s1*y+s2*z\).
When the layout_type of logical tensor is opaque, users are not supposed
to interpret the memory buffer directly. An opaque tensor can only be output
from oneDNN Graph’s compiled partition and can only be fed to another compile
partition as an input tensor.
Low Precision Support#
oneDNN Graph extension provides the same low precision support as the
oneDNN primitives, including u8, s8, bf16 and f16.
For int8, oneDNN Graph API supports quantized model with static
quantization. For bf16 or f16, oneDNN Graph supports deep learning
framework’s auto mixed precision mechanism. In both cases, oneDNN
Graph API expects users to convert the computation graph to low
precision representation and specify the data’s precision and
quantization parameters. oneDNN Graph API implementation should
strictly respect the numeric precision of the computation.
For int8, oneDNN Graph API provides two operations dequantize and
quantize. Dequantize takes integer tensor with its associated scale
and zero point and returns f32 tensor. Quantize takes an f32 tensor,
scale, zero point, and returns an integer tensor. The scale and zero
point are single dimension tensors, which could contain one value for
the per-tensor quantization case or multiple values for the
per-channel quantization case. The integer tensor could be represented
in both unsigned int8 or signed int8. Zero point could be zero for
symmetric quantization scheme, and a non-zero value for asymmetric
quantization scheme.
Users should insert Dequantize and Quantize in the graph as part of quantization process before passing to oneDNN Graph. oneDNN Graph honors the data type passed from user and faithfully follows the data type semantics. For example, if the graph has a Quantize followed by Dequantize with exact same scale and zero point, oneDNN Graph implementation should not eliminate them since that implicitly changes the numerical precision.
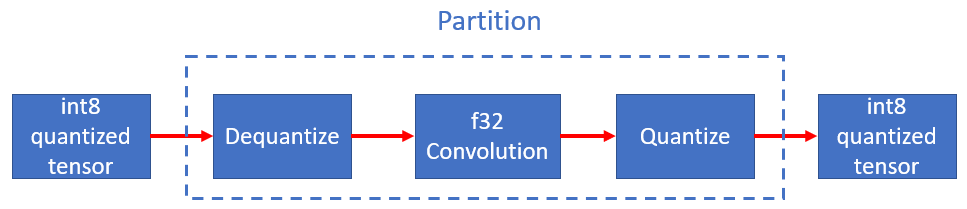
oneDNN Graph partitioning API may return a partition containing the Dequantize, Quantize, and Convolution operations in between. Users don’t need to recognize the subgraph pattern explicitly and convert to fused op. Depending on oneDNN Graph implementation capability, the partition may include more or fewer operations.
For bf16, oneDNN Graph provides the typecast operation, which can
convert an f32 tensor to bf16 or f16, and vice versa. All oneDNN Graph
operations support bf16 and f16. It is the user’s responsibility to
insert TypeCast to clearly indicate the numerical precision. oneDNN
Graph implementation fully honors the user-specified numerical
precision. If users first typecast from f32 to bf16 and convert back,
oneDNN Graph implementation does the exact data type conversions
underneath.
